Thoughts on
Declarativeness
What it means, when to use it, and how to shape it
DSLs are supposed to be
“declarative”. People say this, but it is not clear what they mean with it. So
let us unpack this a little bit. What does it mean for a language to be
declarative? Here is the definition from
Wikipedia:
In computer
science, declarative programming is a programming
paradigm— a style of building the structure and elements of computer
programs — that expresses the logic of a computation without
describing its control flow.
Ok, this is useful. But then,
is a pure functional language declarative? After all, it has trivial control
flow (the call graph is the control flow graph) and no side-effects. If so,
what is the difference between functional and declarative? Wikipedia continues
to say
[describe] what the program must accomplish in
terms of the problem domain, rather than describe how to
accomplish it as a sequence of the programming language primitives.
This is essentially the
definition of a (good) DSL. So are all DSLs declarative?
Another definition I have
seen points out that a declarative program is one that does not even have a
predefined execution order (a functional program has this). In other words,
there is some kind of “engine” that processes the program by finding out an
efficient way of “working with the program” to find a solution.
Solvers & Constraint-based
Programming
Solvers are examples of such
engines. They take as input a couple of equations with free variables, and try
to find value assignments to these variables that satisfy all the equations.
For mathematical equations, we know the problem from school:
Eq1: 2 * x == 3 * y
Eq2: x + 2 == 5
Eq3: 3 == y + 1
A solution for this set of
equations is x := 3, y := 2. Solvers that solve this
kind of equations, are called SMT solvers. SMT stands for “Satisfiability
Modulo Theories”; the “Theories” part relates to the set of abstractions it can
work with. For example, in addition to to arithmetics, they can also work with
other “theories”, such as logic or collections. Modern SMT solvers, such
as Z3, can
work with huge sets of equations and large numbers of free variables, while
still solving them in very short time (sub-second). For more details on the use
of solvers in DSLs, and lots of related work, see Section 5 in the Formal Methods booklet.
Note that these equations do
not imply a direction — they can be solved left to right and right to left,
because they only specify constraints on the variables. This is why this
approach to programming is also called constraint-based programming.
It is possible to encode
structure/graphs as equations (also called relations). Once we have done this,
we can “solve for structure”, i.e., we can find structures that satisfy the
other constraints expressed in the equations. For example, one can express the
data flow graph as a set of relations over the program nodes and then perform
dataflow analyses, ideally incrementally. The INCA paper by
Tamas Szabo, Sebastian Erdweg and yours truly explains how to do this.
Such constraints can also
represent some notion of cost, for example, the needed bandwidth for a network
connection. In this case, a solver is used iteratively. Czarnecki et al. perform
multi-objective optimisations for structural and variable models. A
hello-world example is also in the Formal Methods booklet.
The constraints can also be
used to express structural limitations (such as visibility rules in program
trees). We will return to this later.
This is all very nice. But
solvers have three problems. First, encoding non-trivial problems as equations
can be tough. This is especially true for structures. Second, depending on the
number, size and other particular properties of the equations, the required
memory and/or performance can be a problem — it does get big and slow quickly,
again, especially for structures And finally, because the engine uses all kinds
of heuristics and advanced algorithms to find solutions efficiently, debugging
can be a real nightmare.
State Machines and Model
Checking
Are state machines
declarative? Well, I don’t know. They do encode control flow (in particular, as
reactions to outside events). They also change global state (which is where
their name comes from). And that state potentially evolves differently,
depending on the order (and timing, in timed state-machines) of incoming events.
So this pretty much makes state machines as non-declarative as you can get.
But is this really a useful
definition? One reason why people use state machines is that they can be
analyzed really well. The whole field of temporal logic and model checking (see
Section 6 in the Formal Methods booklet) is about verifying properties on
state machines. The reason why this works is that they make state and the way
it evolves explicit using first-class language constructs. I will discuss model
checking in a future post.
Alternative Definition of
Declarativeness
Let me propose another
definition of declarativeness. It might sound overly pragmatic, but it is
nonetheless useful:
Declarativeness: A declarative language is one that makes
those analyses simple/feasible that are required for the use cases of the
language.
This reemphasises a core idea
underlying the Formal Methods booklet: you should consciously design a
language in a way that makes analyses simpler; usually by making the right
things first class. In the rest of the post I show two examples of meta
languages (i.e., languages used in language definition) that illustrate the
point.
Scopes
In a
language workbench like MPS, programs are represented as graphs. The
containment structure is a tree, but there are cross-references as well. For
example, a Method contains
a Statement, a Statement might
contain a VariableRef (a particular kind of Expression), which in turn references a Variable defined
further up in the method. The language structure only talks about concepts: a VariableRef has a
reference var that points to a Variable. But it
does not specify which variables. Scopes are used to define the set of valid
reference targets (Variables in this example). They are a way of implementing visibility rules
in a language.
Scopes as Functions
A scope can be seen as a
function with the following signature:
fun scope(node<T> n, Reference r): set<U>
In our example, T would be VariableRef, r would
represent the varreference, and U would be Variable. A naive
implementation of a scope can be procedural or functional code that returns,
for example, the set of all Variables in the current method
(let’s ignore order and nested blocks for now) as well as the GlobalVariables in the
current program. The example below encodes the particular reference for which
we define the scope in the name of the function:
fun scope_VariableRef_var(node<VariableRef> n): set<Variable>
= {
n.ancestor<Method>.descendants<Variable> union
n.ancestor<Program>.descendants<GlobalVariable>
}
So far so good. Whenever the
user presses Ctrl-Space to see the set of valid reference targets (or when an
existing reference is validated by the type checker), the system can simply
call this function and use the returned set for display in the menu (or for
testing if the current target is in the set).
Creating Targets
Let us now introduce an
additional requirement. Let’s say, the user wants to reference something that
does not yet exist. Since a projectional editor like MPS establishes references
eagerly (as opposed through lazily resolved names), the target element must
actually exist for us to be able to establish the reference. We can’t
write down a method name (with the intention to call it), and then later fill
in the method; the reference cannot be entered! To still support top down
programming, we have to be able to implicitly create missing targets. So if a
user presses Ctrl-Space in the context of a VariableRef, in addition to
choosing from existing targets (computed by the scope), the tool should provide
one-click actions for creating new targets (through a quick fix or a special
part in the code completion menu).
Here is the catch: the
one-click target creators should create valid targets. So they
have to somehow find out, where in the program which kinds of targets would be
valid and only propose those. Extracting this information from the scope
definition above (or even worse, one written in a procedural language) is
really quite hard.
Solver-based Solution
In some sense, we have to
“forward-evaluate” the scope to find the places where, if a node existed there,
it would be a valid target for the reference. Solvers can do just this. If we
formulate the program structure and the scopes as constraints, transform the
current program to a set of equations and then ask the solver to solve them (in
the right way), this would solve the problem quite elegantly. People have
worked on this, see for example Friedrich Steimann’s work (here, here and in particular, here).
However, the performance and memory requirements, as well as the (from most
developers’ perspectives) non-intuitive way of specifying the constraints makes
this approach challenging in practice. Hundreds of MB or even GBs of memory for
relatively small programs is common. Currently, I cannot see how to use this in
practice.
Structure-based Declarativeness
Consider the following scope
definitions:
scope for VariableRef::var {
navigate
container Method::statements
path
node.ancestor<Method>
navigate
container Program::contents
path
node.ancestor<Program>
of GlobalVariable
}
This has the following
structure and semantics. A scope defines which concept and which reference it
is for (here: var in VariableRef). It then
contains multiple separate definitions of where targets can be found. Each one
specifies a container location (the statements collection
in a Method or the contents of a Program) as well as a path expression
of how to get there from the perspective of the current node. The execution
algorithm is as follows: for each navigate block, execute the path expression
from the current node to get to the container nodes. Then grab all the nodes in
the specified container slot (statements or contents), but only
select those that are of the compatible concept, or those explicitly specified
by the of clause.
For our second use case, the
creation of missing targets, we don’t have to perform any magic: we create an
action for each of the navigate blocks (so in the
example, we’d get two, as expected). To execute the action, we execute exactly
the same path expression to lead us to the container nodes, just as
when we evaluate the scopes. We then create the new nodes in the slot defined
by the container.
For this to work we don’t
need a solver, we do not have to “forward-evaluate” (or solve) anything. The
path expressions can be as complicated as they want to be, we can filter, or
compute anything we want …
path node.ancestor<Method>.where(
it.statements.size < 10
&& !it.name.endsWith(“X”))
… because we always only
evaluate it as a functional program. And there is no performance problem, we
just “execute” code. There are, of course, limitations. We cannot express more
complex structural constraints. But this was not the goal. Below is a screenshot
of a working example of a somewhat more complex set of scoping rules:
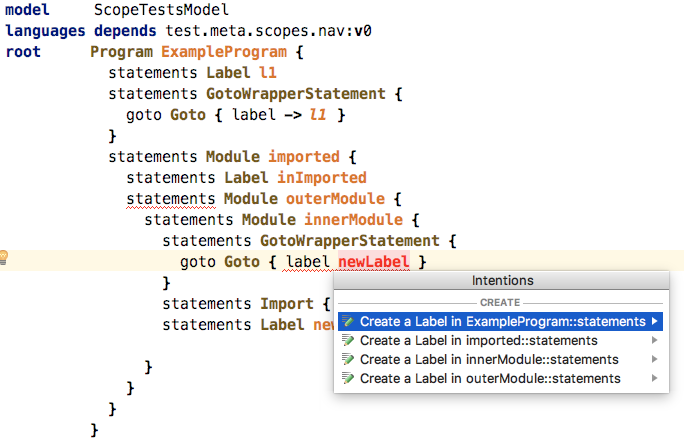
Even debugging such scope
definitions is not a real problem, because, again, there is no real advanced
magic going on: it is a mix of function evaluation and some specific (but
straight-forward) debug support for the declarative parts. I will revisit
debugging of these and other DSLs in a future post.
Type Systems
Type systems are primary
candidates for declarativeness. In fact, MPS itself uses a type equations and a
solver to compute types. Let me give an example.
MPS Type System DSL
Imagine you want to compute
the type of the following list:
val l = list(1, 2, 23.3)
The list contains ints and floats, and in most
languages, the resulting type would be list<float> because float is a
supertype of int. In other words, the
resulting type is a list type of least common supertype of the elements of the
list. Here is how MPS expresses this rule:
typing rule for ListLiteral as l {
var T;
foreach e in l.elements {
T :>=: typeof(e)
}
typeof(l) :==:
<ListType(baseType: T)>
}
This code first declares a
type variable T. It then iterates over all elements in the list
literal and adds an equation to the set of equations that
expresses that T must be the same type or a supertype (:>=:) of the type
of the element ewe are currently iterating over. At the end of the foreach we have
created as many equations as there are elements in the list literal, all of
them expressing a constraint on the variable T. Next we
create another equation that expresses that the type of the list literal l (the
thing we are trying to find a type for) must be the same types as (:==:) a ListType whose
base type is T. All of these equations are then fed to a solver
who tries to find a solution for the value of T.
Another example. Consider a
language with type inference. When you declare a variable, it can be
· Only a name and a type; the type of the
variable is then the explicitly given type (var x: int).
· Only a name and an init value; in this case
the type of the variable is inferred from the init expression (var x = 10).
· A name, type and an init expression; the
type is the explicitly given one, but the init expression’s type must be the
same or a subtype of the explicitly given one (var x: int = 10).
The typing rule that
expresses this is given here:
typing rule for Variable as v {
if v.type != null then
typeof(v) :==: typeof(v.type)
else typeof(v)
:==: typeof(v.init)
if v.init != null then
typeof(v.init) :<=: typeof(v)
}
The MPS type system language
is quite powerful. For meaningfully-sized programs it performs well, mostly
because it is updated incrementally. MPS tracks changes to the program and then
selectively adds and removes equations from the set of equations considered by
the solver. The solving itself is also incremental.
The nice thing about the MPS
type system DSL is — surprise! — its declarativeness. MPS supports language
extension and composition, and the type system fits in neatly: and extension
language just adds additional equations (constraints) to the set of type
equations considered by the solver. There’s no fuzz with execution order or
extension points or anything.
However, it has one major
weak spot: debugging. If your type system does not work, there is a debugger.
All it does, essentially, is to visualise the solver state. If you don’t
understand in detail what the solver does, this is rather useless. I have heard
rumours that there is somebody in Jetbrains’ MPS team who understands the
debugger, but I haven’t met the guy yet :-)
Type Systems expressed through Functions
A much simpler way for
expressing type systems is functions: you can imagine every language concept to
essentially have a function typeof that returns its type. In that function you
explicitly call the typeof functions of other nodes. You define the order
explicitly, usually bottom-up! It runs as a simple functional program, with
good performance, and debugging is easy. There’s no constraints, no
execution-order independence, and it is a bit harder to extend (because of the
execution order).Many language workbenches, including Xtext, use this approach.
Structure-based Declarativeness
Let us now look at the
following typing rule for the variable declaration:
typing rule for Variable as v =
primary v.type :>=: secondary
v.init
Here is its semantics: if a v.type is given,
then it becomes the result type; the v.type wins, it is the primary. If no v.type is given,
then the secondarywins, the v.init in this
case. If both are given, the primary still wins, but the secondary must be
the same or a subtype of the primary.
For the list literal example,
the typing rule is:
typing rule for ListLiteral as l =
create ListType[baseType: commonsuper(l.elements)]
}
It is so obvious, I don’t
even have to explain what it does.
Both of these are much
shorter, more expressive, and can be evaluated without a solver. The reason for
this is that we have created direct, first-class abstractions for the relevant
semantics — the language is declarative!
Debugging is straightforward
by the way, the debugger can simply “explain” what is going on: v.type is null, so taking v.init: float.
There is of course an obvious
drawback as well: you have to implement more, and more specific language
abstractions, essentially one for every typing idiom you want to support (or
you provide a fallback onto regular functional programming). However, we expect
there to be fewer than 20 of such idioms to express the vast majority of
relevant type systems. Implementing those with a tool like MPS is not a big
deal — certainly more feasible than implementing a fast solver!
Wrap up
In this post I have
illustrated what I mean by declarative: a language where the analyses I am
interested in are expressed first-class. I have explained the idea based on two
meta languages (for scopes and type systems). Those, by the way, have been
taken from a new set of language definition DSLs we are working on. Stay tuned,
you will read much more of those in the future :-)