Dealing with Mutable
State in KernelF
Boxes, State Machines and Transactional Memory
In the previous post I discussed various characteristics
functional programming languages might have, concepts such as purity, caching,
idempotency (I got comments that higher-order functions, laziness and currying
were missing. I agree. They were missing). We finished that post with the idea
of effect tracking, i.e., making it explicit, and thus, more easily analysable,
where an effect happens. This way, the IDE can report errors if effects occur
in places where it is not allowed (for example, in preconditions) and exploit
purity in the execution, for example through caching.
We also discussed that one
usually uses immutable data structures in functional languages because, in
order to cache previous results of functions, those values cannot change once
they have been “released to the wild” by a function (there are other reasons
why immutable data is useful as well).
In this post I will discuss
further the handling of state in functional programs.
Boxes
Immutable data means that you
cannot change a value once it has been created. For primitive types, this is
rather intuitive. For example in …
val a = 1 + 2
val b = 3 + a
val x = a + b
… it is rather intuitive that
1+2 creates a new value 3, and that adding a and b creates a
new value c. It’s maybe not so obvious that you cannot
reassign a variable later:
val x = a + b
x = x + 1 // invalid
The problem with this is that
anybody who has a reference to x now sees the value of x changing.
So you have to invent a new name for the new value (this can sometimes be a bit
annoying).
Let us look at collections.
Assume you have a list of three elements and you add a fourth one:
val l1 = list(1, 2, 3)
val l2 = l1.plus(4)
assert l1.size == 3
assert l2.size == 4
So here, too, the original
list remains unchanged and you get a new list, one that now has a fourth
element, as the result of l1.plus(4).
So, how then, do you store
changing global state, for example, a database of measurements? Using a new
variable for each update “state of the database” is not a solution because it
is *the* database that is supposed to change. One solution would be to
introduce variables (as opposed to the values used so far):
var db = list(1, 2, 3) // note the r instead of the lfun store(x: int)
{
db.add(x)
}
So, for this to work, you
will have to mark the add method to have an
effect, which will, transitively, also give store an effect. That’s fine,
this is what effect tracking is for. And the whole purpose of this function is
to have an effect, so all is good. But: you need a whole second set of APIs for
mutable collections. The list in this example cannot
be the same list as the one used
earlier; it’s a different class, a mutable list, called mlist. You need
mutable versions of all collections. This approach is a valid solution, and
some languages, for example, Scala, use it.
There is another approach
that does not require a second set of types: boxes. You explicitly package a
value inside a box. The box itself is immutable (i.e., its own reference stays
stable), but its contents can change:
val globalcounter: box<int> = box(0)fun
incrCounter() {
globalcounter.update(globalcounter.val
+ 1)
}
Apart from creation, boxes
have two methods: a val that returns the
contents of the box, as well as a update() method that sets a new
value. The former has a read effect, the latter a modify effect.
When you update the box’s content, you pass a new value, so you don’t need
additional APIs for changing value — the boxes themselves are generic:
val db = box(list(1, 2, 3)) // we're back to a value here!fun
store(x: int) {
db.update(db.val.plus(4))
}
Now, while this approach is
nice because you can stick with the original immutable APIs (plus the generic
box functionality), it is also annoying because the usage syntax is kinda
awkward. You can’t completely get rid of this, but you can make it less awkward
by providing concise access to the current content of the box through the it expression:
val globaxlcounter = box(0)
val db = box(list(1,
2, 3))fun incrCounter() { globalcounter.update(it + 1) }
fun store(x: int) { db.update(it.plus(4)) }
So that’s not quite as bad.
In fact, I think it’s ok! There’s another nice example: in a concurrent
setting, you can build it so that the it is initialized only
once at the very beginning of the update, and the value stays stable even if
the box contents change (and you reference it multiple times).
KernelF uses this approach. I
think it is very similar (identical?) to what Clojure does;
boxes are called refs there.
In terms of implementation,
for example, in an interpreter, boxes are really just wrapper objects with a
method to get and set a generic java.lang.Objectbox content. The val and update operations
are interpreted by the interpreter to call those methods on the runtime Java
object.
public class BoxValue {
private Object value;
public BoxValue(Object initial)
{ this.value = initial; }
public void set(Object
newValue) { this.value = newValue; }
public Object get() { this.value;
}
}
Native Mutable Data
The embodiment of changing
state are state machines (surprise!). Here is a minimal one that represents a
(slightly contrivted) counter:
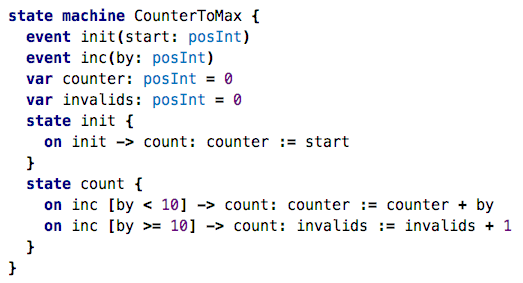
It defines two events (i.e.,
ways to trigger the machine), one to initialize the machine’s counter, and the other
one to increment it. It has two states, an initial state and operational state.
The init event goes from the initial initstate to the count state,
where it then accepts inc events. If the by value is
less than 10, the counter gets incremented,
otherwise a counter of invalidsincrementation attempts is
increased (yeah, it’s a contrived example, but it’s simple).
The state machine (surprise
again) is inherently stateful. So we don’t have to pretend anything’s
immutable. This is why we allow an assignment operator := inside a
state machine. Inside a state machine you can also read one of its variables by
just mentioning its name (as in invalids +
1); you don’t need the val. This is kinda
interesting from an interpreter perspective, because if a variable name is
mentioned on the left of the assignment operator, it must evaluate to a box (so
you can set the new value), and if it is used elsewhere, you want to evaluate
to the contents of the box (in order for the existing implementation of, for
example, the + to continue to work). Luckily, the AST
structure makes it obvious whether a box or a value is required (relevant for
type checking and for execution): you need the box if and only if it is used in
the left slot of an assignment.
So how do you use a state
machine? Here is how:
val ctr = start(CounterToMax).init(0) // start instantiates a SMfun
doStuffWithCounter() {
ctr.inc(5) // now 5
ctr.inc(3) // now 8
ctr.inc(20) // invalid; still 8
assert ctr.counter == 8
assert ctr.invalids == 1
}
Note that even though there
is mutable state all over the place (and the various operations on state
machines have effects!), there are no boxes to be seen. You don’t need an update, you don’t
need val on anything. Why is this?
Well, internally the state
machines still have box semantics (in the implementation, a bunch of interfaces
for IBoxLike things are used to generalise box-like
behavior). But state machines have been purpose-built to have state, there is
no need to reuse existing immutable APIs, as was the case for primitive
operators and collections.
Let’s look at the
interpreter. To implement the variable references inside state machines, we use
an interface ICanBeUsedAsLValue to mark that they can
be used on the left side of an assignment (an “lvalue”). The interface has a
method isUsedAsLValue that detects structurally, from the AST, if a
particular variable reference is on the left side of an assignment. The
interpreter uses this method to determine what it needs to evaluate to. Here is
the generic interpreter for the assignment; note how it relies on the runtime
representation of things that can be lvalues to implement the ILValueinterface to
generically implement this functionality:
Object rvalue = #right; // recursively call interpreter on right
Object lvalue = #left; // and left
arguments
if (lvalue instanceof ILValue) { // must be an ILValue
((ILValue) lvalue).updateValue(rvalue);
// which has update method
} else {
throw new
InvalidValueException(node.left, "not an ILValue");
}
return rvalue;
In the case of state
machines, the interpreter plays together with, the VarRefconcept that
represents references to state machine variables. Look at its interpreter:
SmValue currentMachine = (SmValue) env[SmValue.THIS];
SMVarValue value = currentMachine.getVar(node.var);
if (node.isUsedAsLValue()) {
return value; // returns the box
} else {
return value.value(); // returns box contents
}
It first retrieves the
currently executing instance of the state machine from the environment (the
triggers put that there), and then asks the current state machine for the
variable that it references. Note that this returns the ILValue-implementing
class that represents the variable. Then comes the crucial distinction: if the
current variable reference is used in lvalue position, we return the ILValue (so that
the assignment interpreter can call update). Otherwise we directly return the
contents of the box (e.g., an int)
We are not going to discuss
the implementation of the state machine’s behavior itself; it’s a bunch of if statements
like any other state machine. What is important though, is that the current
total state of the machine (the current state plus the values of all its
variables) is also an immutable object. This will become important for state
machines to work with transactions, as shown next.
Transactions
Take a look at the following
code:
type intLE5: int where it <= 5
val c1: box<intLE5> = box(0)
val c2: box<intLE5> = box(0)fun
incrementCounters(x1: int, x2: int) {
c1.update(it + x1)
c2.update(it + x2)
}
fun main() {
incrementCounters(1, 1)
incrementCounters(3, 5)
}
Boxes respect the constraints
on their content type: if you set a value that violates the constraint, than
the update fails. What actually happens then is configurable, at least in
KernelF’s default interpreter: output a log message and continue, or throw an
exception that terminates the interpreter. While, in the second case, the
program stops anyway, and it doesn’t really matter which value is set, in the
first case we run into the problem that, for the second invocation of incrementCounters, c1 is updated
correctly, but the update of c2 is faulty. In many
cases, this is not what you want.
So what can you do? Enter
transactions.
fun incrementCounters(x1: int, x2: int) tx{
c1.update(it + x1)
c2.update(it + x2)
}
A transaction block is like a
regular block, but if something fails inside it (interpreter: an exception is
thrown), it rolls back all the changes. This is really easy to implement:
remember that values are immutable. So you can simply grab the value of each
box (or more generally, ITransactionalValue) before you perform the update and
remember them in the transaction. If you have to rollback, you just re-set the
value you remembered. Real easy.
This also works with state
machines, and with combinations of state machines and other boxes, as shown in
the example below where the state machine modifies other global data.

Finally, the framework also
supports nested transactions (which can be rolled back individually) as well as
the distinction between starting a new transaction (with newtx) and a block
requiring to be executed in an existing transaction (using intx).
Remember how above I said
that the current total state of a state machine is also an immutable object; in
other words, it also implements ITransactionalValue. The implementation of the
transaction in the interpreter looks like this:
Transaction tx = new Transaction(node);
env[Transaction.KEY] = tx; // store in env for nested calls
try {
Object res = #body;
tx.commit();
return res;
} catch (SomethingWentWrong ex) {
tx.rollback();
} finally {
env[Transaction.KEY] = null; // no tx active anymore
}
Now, if you are in a
concurrent setting and you need isolation you have to do a bit more work to
implement transactions reasonably.
· You want thread B not to see changes to
global state performed in a transaction in thread A. So instead of updating the
boxes and rolling back in case of a problem, you just record the updated value
in the transaction itself and only upon commit (when nothing failed) you
actually updatethe boxes.
· Inside the transaction, however, you do want
a call to .val to return the value you may have set
earlier in the transaction. So .val has to check whether the current
environment contains an active transaction, and if so, return that temporary
value stored in that transaction, if any.
· And finally, during commit, when you
actually set the value, you want to check if it has been changed by another
transaction in the meantime (easy to do, it’s just an identity check because
values are immutable!). If so, you abort and don’t really commit.
This form of transactional memory
is also used in Clojure, as far as I understand (please correct me if I am
wrong).
Wrap Up
A few comments before we
close. The boxes, assignment and transactions are a generic framework offered
by the mutable extension of KernelF. Any stateful language construct can be
integrated by implementing interfaces like ILValue or ITransactionalValue and adhering to a few idioms (such as checking whether an ICanBeUsedAsLValue is
actually used on the left side of an assignment, an then returning the box).
Further, implementing this
functionality in KernelF really helped me understand how the “magic” works in
languages like Clojure. It also helped me appreciate the use of immutable data.
I am getting more and more convinced that this is the way to go. One criticism
about immutable data structures is their overhead. In particular, for
collections, graphs and maps you have to copy things all the time. Not true!
Modern implementations of persistent data structures, i.e., immutable data
structures with sharing of unchanged parts, are really efficient. A recent
workshop with Michael
Steindorfer as well as some benchmarks we did in the context of a
different project made that point very impressively.
Lastly: in some sense,
functional languages and immutable data are more “primitive” than imperative or
object-oriented languages, they just do less. However, combining this with
language extensions that directly support relevant patterns, whether generic as
discussed in this post, or domain-specific as in pattern number three here, can compensate for those
“shortcomings” without compromising the appealing semantics of functional
languages.